search_vulns: A Deep Dive into its Technologies and Approaches
A typical challenge in IT security is determining whether a particular software product is affected by any known vulnerabilities. In our first post we illustrated that finding known vulnerabilities is surprisingly complex. More specifically, we devised requirements a good solution should meet and compared several established tools in regards to these requirements. Since we identified several weaknessses in all of these tools, we developed our own solution search_vulns. In our second post, we introduced search_vulns and showed how it compares with the other tools. We concluded that it solves many of the identified challenges and is thereby not affected by the mentioned weaknesses of other tools. In this third and final post, we explain how search_vulns works in detail and show how it solves the previously identified challenges that other tools do not.
We begin this post by providing an overview of search_vulns' (technical) architechture. Thereafter, we illustrate how a user's textual query is matched to a CPE string, as well as some related challenges and solutions. Next, we describe how the matched CPE is used to search for known vulnerabilities, again with related challenges and solutions along the way. Then, we briefly show how exploits and other information is matched to vulnerabilities, as well as how the recency of the queried sofware is determined. The complete table of contents is as follows:
- Architecture
- Matching User Queries to CPEs
- Matching Vulnerabilities and Exploits to CPEs
- How Exploits and Other Information is Matched To Vulnerabilities
- Including Software Recency Status from endoflife.date Data
- Recaptcha & API
- Summary, Conclusion and Future Work
Architecture
The (technical) architecture of search_vulns is illustrated in the following picture:
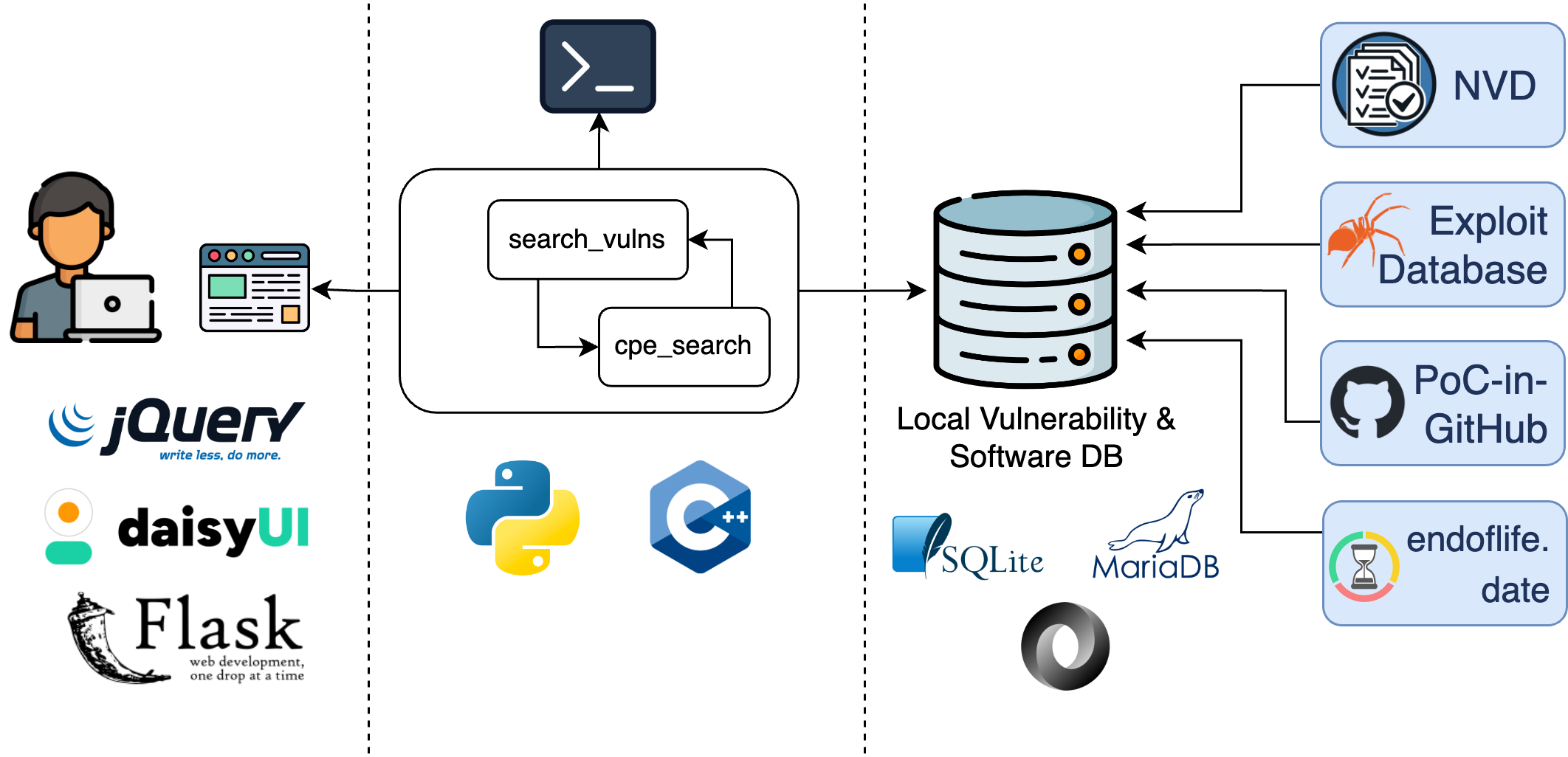
On the right side, we start by building our local vulnerability and software database, based on our currently three data sources. The core of the database can be stored via SQLite or MariaDB. Additionally, more lightweight data, like deprecated and otherwise equivalent CPEs, are stored in JSON files.
To match a user's textual query to a CPE string, search_vulns utilizes its submodule cpe_search. Once search_vulns has obtained a CPE string, it searches for vulnerabilities, exploits and further information about the referenced software. Both search_vulns and cpe_search are mostly written in Python. However, the build code for the vulnerability database is written in C++ and compiled. The reason for this is performance: The vulnerability data is quite large and some processing needs to take place, which simply takes to long with interpreted, extensive Python code. Users who have search_vulns installed themselves can use the provided command line interface or Python bindings.
Lastly, the backend of the web service component is built using Flask. The scalability can optionally be increased by using gunicorn for multiprocessing and a reverse proxy like Apache or Nginx. For the design of the frontend, Tailwind CSS and more specifically DaisyUI are used. Logic in the frontend is implemented via JavaScript and jQuery.
Matching User Queries to CPEs
search_vulns uses the NVD as central vulnerability database. On an abstract level, the NVD stores information about which software is affected via a list of CPEs. Therefore, the first challenge search_vulns has to overcome is matching a user's textual query to a fitting CPE. Our cpe_search submodule accomplishes this with custom algorithms and techniques that attempt to retrieve the best matching CPE from the NVD's official CPE dataset. This is explained in more details below.
The Algorithms and Mathematics Behind cpe_search
Essentially, the NVD's CPE dataset is a very large JSON array of products, including their title, cpeName and deprecated-status. For example, we can retrieve the very first entry of the dataset with the URL https://services.nvd.nist.gov/rest/json/cpes/2.0?resultsPerPage=1&startIndex=0:
{
"resultsPerPage": 1,
"startIndex": 0,
"totalResults": 1259898,
"format": "NVD_CPE",
"version": "2.0",
"timestamp": "2024-02-20T17:17:33.053",
"products": [
{
"cpe": {
"deprecated": false,
"cpeName": "cpe:2.3:a:3com:3cdaemon:-:*:*:*:*:*:*:*",
"cpeNameId": "BAE41D20-D4AF-4AF0-AA7D-3BD04DA402A7",
"lastModified": "2011-01-12T14:35:43.723",
"created": "2007-08-23T21:05:57.937",
"titles": [
{
"title": "3Com 3CDaemon",
"lang": "en"
},
{
"title": "スリーコム 3CDaemon",
"lang": "ja"
}
]
}
}
]
}
In addition to the actual product data, the data "header" contains information about the total number of results, the number of results returned per (logical) page and the page we are currently on. In summary, this allows search_vulns to effectively download the entire dataset and build its own local software database.
With all of this data, the core challenge is how to find the best matching product for a user's query. The fact that the user may only know some words of the product's title, which may not even be in order, makes this even more challenging. Displaying all possibly matching results to the user, based on a simple word comparison, and having them choose the right one is one way to solve this challenge. However, this requires more work from the user, can be more computationally intensive and lastly is not possible in automated workflows. An alternative solution is maths: To enable the user to be as flexible as possible with their input, search_vulns utilizes a metric called Term Frequency (TF), which is usually used in the context of search engines and text retrieval. The general idea of this metric is to represent text and phrases as data vectors and mathematically compute a similarity score.
Take for example the user query Apache Airflow Server 2.4.0 and the official product name Apache Software Foundation Airflow 2.4.0. First, we create a bag of words containing all involved words, i.e. ["Apache", "Airflow", "Server", "2.4.0", "Software", "Foundation"]. From this bag of words we can derive a vector that represents the term frequencies of any phrase that contains only these words:
$$$tf_{phrase} = \begin{pmatrix} tf_{Apache} \\ tf_{Airflow} \\ tf_{Server} \\ tf_{2.4.0} \\ tf_{Software} \\ tf_{Foundation} \end{pmatrix}$$$
Since each phrase contains these words either once or not at all, their vectors look like the following:
$$$tf_{query} = \begin{pmatrix} 1 \\ 1 \\ 1 \\ 1 \\ 0 \\ 0 \end{pmatrix} \qquad ; \qquad tf_{product} = \begin{pmatrix} 1 \\ 1 \\ 0 \\ 1 \\ 1 \\ 1 \end{pmatrix}$$$
To compute a similarity between these two vectors, i.e. phrases, of length $n$ several approaches exist. search_vulns uses Cosine Similarity. Here, the similarity between these two vectors is computed like the following:
$$$cos(\theta) = \frac { tf_{phrase} \cdot tf_{query} } { \lVert {tf_{phrase}} \lVert \, \lVert {tf_{query}} \lVert } = \frac {\sum_{i=1}^{n} {tf_{phrase_i} \cdot tf_{query_i}}} {\sqrt {\sum_{i=1}^{n} {tf_{phrase_i}^2}} \cdot \sqrt {\sum_{i=1}^{n} {tf_{query_i}^2}}} = 0.67082$$$
Hence, the similarity score between the query and the matching product is 0.67082. Since the score mathematically always lies between 0 and 1, this score is rather high, considering that the query does not contain the words "Software" and "Foundation". Similarly, however, products that do not contain these words have even lower scores. Consequently, this concept enables search_vulns (cpe_search) to effectively match user queries to products.
As is often the case, reality is a bit more complex:
- How do we combine a CPE and its software title into one product phrase?
- In this context, words in the beginning of a phrase are often more important than the ones near the end. For example, a CPE contains the manufacturer and product name in the beginning and minor subversions or edition information near the middle and end. How do we account for this?
- These are a lot of calculations. How can we do this efficiently during runtime?
While search_vulns solves these challenges, this is not described in further detail here. Suffice it to say:
- is solved by creating a unified representation of both values.
- is solved by assigning weights according to the word order of a phrase.
The third challenge is a bit more complicated. Initially, search_vulns solves this by precomputing the values for every product entry in the local software database during its build process. This can be achieved to a great extent, since the similarity comparison is mathematically commutative and some of its components do not depend on the user query. In addition, search_vulns checks which words the query consists of and only performs similarity computations for products that contain at least one query word. This brings the search time down to milliseconds in the average case and at most one or two seconds in the worst case (on general purpose notebooks).
Enhancing User Queries
There is one main disadvantage of this comparison approach based on word comparison: the user needs to know how a product is spelled correctly. In most cases this is easy. However, what about the following software:
Proftpd 1.3.3corProftpd 1.3.3 cas well asOpenSSH 7.4p1orOpenSSH 7.4 p1?Dell OMSAorDell OpenManage Server Administrator?Handlebars.jsorHandlebarsjsorHandlebars js?- THE
Flaskby PalletsProjects or theFlaskpluginFlask CachingbyFlask Caching Project?
Coincidentally, this constitutes to four classes of challenges with this approach:
- Subversions can be spelled differently.
- People like to use abbreviations for long product names.
- JavaScript libraries often include
jsin their name in different ways. People can't be expected to know how some JS library includes theirjs. - If a key word is found relatively more often in a product's name, it is considered more similar.
Generally, search_vulns' submodule cpe_search solves this by enhancing the user's query with general approaches and hardcoded terms. More specifically:
- cpe_search first tries to differentiate between the main and the subversion via the utilized character classes. Then, it creates an internal query that is ran in addition to the original query. For example, the version
7.4p1can be split into the two words7.4andp1, since7.4uses only numbers andp1introduced a letter. - Known abbreviations are hardcoded and can easily be extended. If the user's query contains a known abbreviation, it is spelled out and included into a new internal query.
- cpe_search tries to detect JavaScript libraries and automatically include the possible variations as additional internal queries. For example, a query for any one
Handlebars.js,HandlebarsjsorHandlebars jsresults in all of these three queries to be made internally. - To steer the algorithm more towards the user's intention, additional queries are hardcoded in an extendable way. For example, if the user only queries for
flask, the manufacturerpalletsprojectsis internally included into their query. Note that this does not "break" or "manipulate" the algorithm itself. It merely tries to provide hints based on the user's likely intention if their query lacks too much information to make a distinction between several matching products. On an abstract level, this attempts to include a popularity measure.
Deprecated and Equivalent CPEs
Ideally, a product is always uniquely identified by exactly one CPE. In reality, however, this is not the case. Sometimes the NVD deprecates a CPE for another. For example, all CPEs for Piwik, like cpe:2.3:a:piwik:piwik:0.4.5:*:*:*:*:*:*:*, have been deprecated with ones for Matomo because of a rebranding (see here). As a result, vulnerability databases may miss vulnerabilities if they only search for the old or new software title. Moreover, sometimes there are two CPEs for one product for no reason that is apparent to us. This is the case with Redis for example, where both cpe:2.3:a:redis:redis:*:*:*:*:*:*:*:* and cpe:2.3:a:redislabs:redis:*:*:*:*:*:*:*:* are valid CPEs with known vulnerabilities.
Thankfully, the NVD officially keeps track of deprecated CPEs and their replacement. For example, we can query the NVD's CPE API for piwik via https://services.nvd.nist.gov/rest/json/cpes/2.0?keywordSearch=piwik&resultsPerPage=1&startIndex=0:
{
"resultsPerPage": 1,
[...],
"products": [
{
"cpe": {
"deprecated": true,
"cpeName": "cpe:2.3:a:piwik:piwik:0.2.32:*:*:*:*:*:*:*",
"cpeNameId": "7B924282-085C-4036-A165-732390D8FB31",
[...],
"deprecatedBy": [
{
"cpeName": "cpe:2.3:a:matomo:matomo:0.2.32:*:*:*:*:*:*:*",
"cpeNameId": "DCAE7BD9-677A-4254-941A-20FA72B56D49"
}
]
}
}
]
}
As can be seen above, the API returns the deprecation status in the field products.cpe.deprecated. Even more, the NVD tells us by which new CPE the old one was deprecated via the products.cpe.deprecatedBy.cpeName field. Having stored this information locally as well, search_vulns can treat these CPEs as equal in the context of vulnerability search:
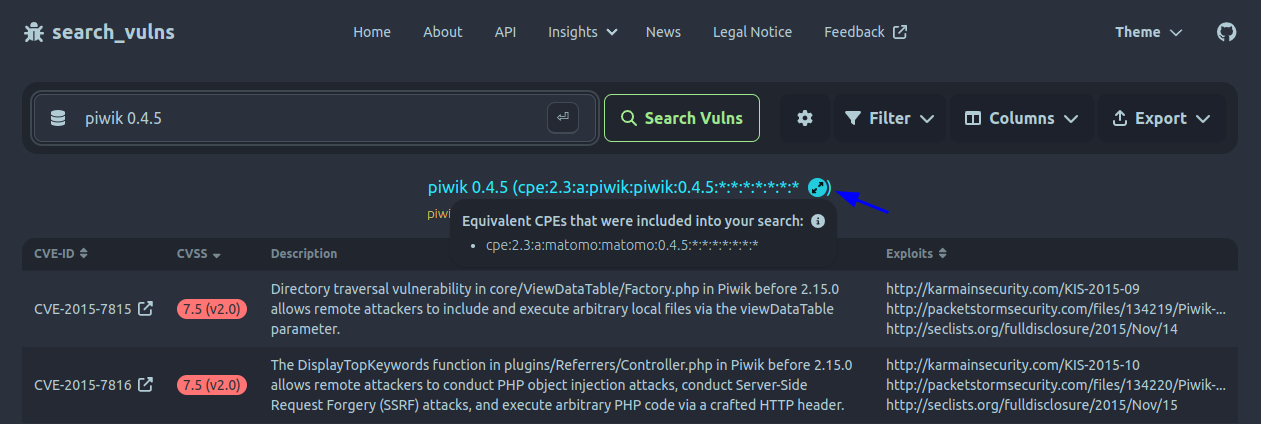
This enables search_vulns to automatically handle deprecated CPEs and return valid results. Unfortunately, there is no list that keeps track of multiple CPEs for a single product, where the reason is not deprecation. Thus, search_vulns has to store additional "equal" CPEs manually. This is implemented in a extensible way, however, such that if new cases appear they can be included into the tool easily.
No Match: What If a CPE Does Not Exist
Occasionally, search_vulns may not be able to automatically retrieve a CPE for a user's query.
Rarely, the reason for this is that the NVD's CPE dictionary does not contain a CPE for the software product. For example, this is the case with Simple DNS Plus (cpe:2.3:a:simpledns:simple_dns_plus:*:*:*:*:*:*:*:*), which cannot be found in the NVD's CPE dictionary. Nevertheless, since CVE entries for this software exist, the CPE can be retrieved from the NVD's vulnerability data. One needs to take this into consideration and extend the NVD's software database with the additional CPEs contained in the NVD's vulnerability data. Another example is RequireJS (JavaScript library). This software does not have any known vulnerabilities, which likely is the reason that it's not tracked by the NVD at all.
The most common reason for not finding a CPE, however, is that the NVD's CPE database may contain the queried product in general but not in the queried version. This means the NVD's CPE database can sometimes not keep up with new releases of a tracked product. This is especially an issue if the untracked version is affected by known vulnerabilities. Thus, a vulnerability database that only relies on the NVD's official CPEs cannot return precise results in these cases, if they return any at all. To mitigate this issue, search_vulns detects version numbers in user queries and inserts them into the best matching known CPE when needed. This effectively enables users to query for the most recent software versions and retrieve precise results. As an example, check out the query for JFrog Artifactory 4.29.0:
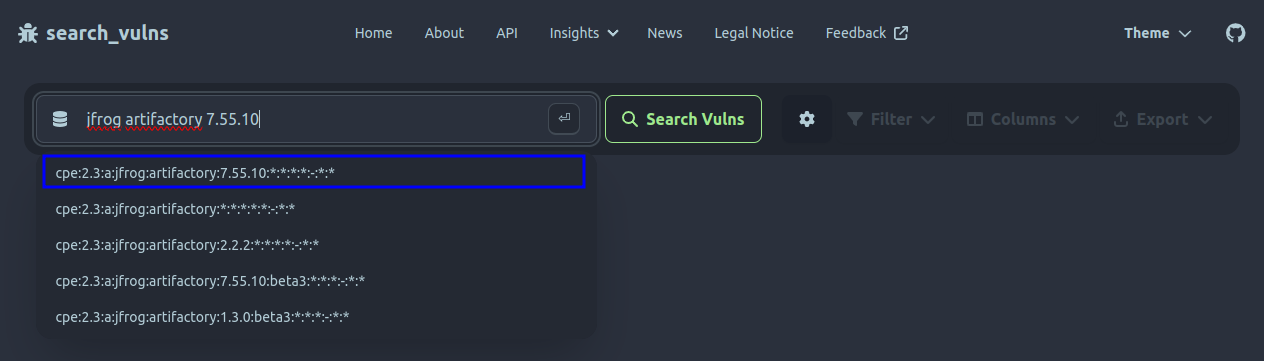
As you can see above, search_vulns manages to grab the query's version (4.29.0) and insert it into the known CPE cpe:2.3:a:jfrog:artifactory:1.3.0:-:*:*:*:-:*:*. The user can then decide to pick the best matching CPE from the provided list of alternative queries.
The third reason why a CPE may not be automatically retrieved for the user's query is uncertainty. As a simple example, if the user's query is just adobe, search_vulns is uncertain which specific product the user meant. Adobe is the manufacturer of many products like Photoshop, Acrobat Reader or Commerce/Magento. For search_vulns to work effectively, the user needs to supply more information which product they meant. To help them, search_vulns suggests a few alternative queries, similar to the screenshot above.
Matching Vulnerabilities and Exploits to CPEs
Once search_vulns has a CPE, it can start searching for vulnerabilities and exploits. First, search_vulns uses the NVD's vulnerability database to search for Common Vulnerabilities and Exposures (CVEs) that affected the queried software. Thereafter, search_vulns uses other data sources to search for exploits for the retrieved vulnerabilities, like the official Exploit-DB or PoC-in-GitHub. Lastly, it determines the software's recency status via data from endoflife.date. The details of this process are explained in the following.
Working With the NVD's Vulnerability Data
The NVD's API provides vulnerability data in the form of a JSON list containing details for every individual CVE. For example, the ten very first CVEs from 1990 can be retrieved from the URL https://services.nvd.nist.gov/rest/json/cves/2.0?resultsPerPage=10. Similar to the NVD's product API described earlier, the vulnerability API also enables user to retrieve all existing CVEs via different query parameters.
In general, there are two ways the NVD stores which CPEs are affected by a vulnerability:
- A generic CPE is stored, which applies to a software product in all of its versions. In addition, seperate version indicators are stored.
- A specific CPE with version information is stored, which applies to only one product in one version.
One example of the first case is CVE-2020-23064:
{
"resultsPerPage": 1,
"startIndex": 0,
"totalResults": 1,
[...],
"vulnerabilities": [
{
"cve": {
"id": "CVE-2020-23064",
[...]
"descriptions": [
{
"lang": "en",
"value": "Cross Site Scripting vulnerability in jQuery 2.2.0 through 3.x before 3.5.0 allows a remote attacker to execute arbitrary code via the <options> element."
}
],
"metrics": {
"cvssMetricV31": [...]
},
"weaknesses": [...],
"configurations": [
{
"nodes": [
{
"operator": "OR",
"negate": false,
"cpeMatch": [
{
"vulnerable": true,
"criteria": "cpe:2.3:a:jquery:jquery:*:*:*:*:*:*:*:*",
"versionStartIncluding": "2.2.0",
"versionEndExcluding": "3.5.0",
"matchCriteriaId": "8BE6EB8F-B9E9-4B1C-B74E-E577348632E2"
}
]
}
]
}
],
"references": [...],
}
}
]
}
As we can see above, the entry includes a multitude of data like a description, dates, CVSS metrics, CWE information, references and (vulnerable) configurations. The configurations contains information about which software is vulnerable and in what combination. The NVD formalizes this with a list of indiviual configuration nodes, which are each comprised of a logical operator and a list of cpeMatches, i.e. product information. The logical operators allow the NVD to specify if products are only vulnerable in a certain combination, e.g. Adobe Acrobat Reader is only vulnerable on Windows or macOS (CVE-2014-8455).
Looking at the configuration node of the example above, the CVE applies to the broad CPE cpe:2.3:a:jquery:jquery:*:*:*:*:*:*:*:*, i.e. jQuery. However, the NVD also supplied a versionStartIncluding and versionEndExcluding value, which means only jQuery between 2.2.0 ≤ x < 3.5.0 is vulnerable. So if the user queries for cpe:2.3:a:jquery:jquery:2.3.1:*:*:*:*:drupal:*:*, search_vulns extracts the version 2.3.1, compares it to the lower and upper bounds of the CVE entry and determines that the queried software is vulnerable. Note that search_vulns also has to make sure that all remaining fields in the two CPEs match: The user queried for jQuery running on the target software drupal only. However, since the vulnerable CPE contains a wildcard in the same position (* or -), jQuery is vulnerable on every target software, including drupal.
One example of the second case, where specific CPEs are stored directly, is CVE-2017-0896:
"configurations": [
{
"nodes": [
{
"operator": "OR",
"negate": false,
"cpeMatch": [
{
"vulnerable": true,
"criteria": "cpe:2.3:a:zulip:zulip_server:1.3.0:*:*:*:*:*:*:*",
"matchCriteriaId": "03ECA4CD-B128-45EA-8A19-5F137BD08690"
},
{
"vulnerable": true,
"criteria": "cpe:2.3:a:zulip:zulip_server:1.3.1:*:*:*:*:*:*:*",
"matchCriteriaId": "0609969D-7C68-4428-A2F3-EA532F6C4045"
},
[...]
]
}
]
}
]
As we can see in this entry, the stored CPEs already contain a version, meaning search_vulns does not have to perform a version comparison. In consequence, checking whether a CVE applies to the queried for CPE is simpler here.
Unfortunately, more complex configurations entries exist, which make deciding whether some software is vulnerable or not more difficult. We have identified the following challenges.
CPEs Have to Be Compared Fully
CPEs have multiple individual fields. All of these fields have to be compared to determine whether a vulnerable CPE definition contains the queried for CPE. This is not particularly difficult, but an inaccurate database may only compare CPE versions.
Seemingly Contradictory Configurations
We have seen some configuration entries that contain some CPE and also a "subset" CPE of this one CPE. Take the query cpe:2.3:a:proftpd:proftpd:1.3.3:c:*:*:*:*:*:* and CVE-2010-4221 for example:
"configurations": [
{
"nodes": [
{
"operator": "OR",
"negate": false,
"cpeMatch": [
[...],
{
"vulnerable": true,
"criteria": "cpe:2.3:a:proftpd:proftpd:1.3.3:*:*:*:*:*:*:*",
"matchCriteriaId": "6402CD88-0255-4574-8772-8723883FBFAF"
},
{
"vulnerable": true,
"criteria": "cpe:2.3:a:proftpd:proftpd:1.3.3:a:*:*:*:*:*:*",
"matchCriteriaId": "6FDFFB0F-0F4D-4388-B5D4-4E217234AADD"
},
{
"vulnerable": true,
"criteria": "cpe:2.3:a:proftpd:proftpd:1.3.3:b:*:*:*:*:*:*",
"matchCriteriaId": "A1D5B657-62CB-4C31-9798-C529C22EA7D6"
},
{
"vulnerable": true,
"criteria": "cpe:2.3:a:proftpd:proftpd:1.3.3:rc1:*:*:*:*:*:*",
"matchCriteriaId": "29FBDF30-0E17-46DA-8548-DEE5E3CD9EAB"
},
{
"vulnerable": true,
"criteria": "cpe:2.3:a:proftpd:proftpd:1.3.3:rc2:*:*:*:*:*:*",
"matchCriteriaId": "D78D0553-7C43-4032-A573-16CC45A24386"
},
{
"vulnerable": true,
"criteria": "cpe:2.3:a:proftpd:proftpd:1.3.3:rc3:*:*:*:*:*:*",
"matchCriteriaId": "FAEEEE3C-7EAA-419F-9BF7-333B63DCDA3F"
},
{
"vulnerable": true,
"criteria": "cpe:2.3:a:proftpd:proftpd:1.3.3:rc4:*:*:*:*:*:*",
"matchCriteriaId": "F68C4EEA-FA42-4B99-8EA6-3DB57527947B"
}
]
Looking at the above excerpt, cpe:2.3:a:proftpd:proftpd:1.3.3:*:*:*:*:*:*:* is vulnerable and so cpe:2.3:a:proftpd:proftpd:1.3.3:c:*:*:*:*:*:* as a "subset" would be too. However, the CVE's description clearly states that ProFTPD before 1.3.3c is vulnerable. Hence, we believe such configuration entries are faulty, meaning search_vulns ignores similar wildcard cpeMatches, where a CPE and a clear "subset"-CPE are both noted as vulnerable.
Comparison of Complex Version Numbers
Some version "numbers" can be quite complex and comparing them difficult. Here are some examples:
- Hitachi Replication Manager 8.8.5-01 (e.g. CVE-2022-4146)
- Citrix ADC 13.1-48.47 (e.g. CVE-2023-3519)
- Cisco UC SME 14su1 (e.g. CVE-2022-20816)
- Huawei UMA v200r001c00spc100 (e.g. CVE-2016-7109)
- Apple iOS 15A5278f (no CVE, just a build number for iOS)
How could you automatically compare these kinds of version numbers, especially if two versions have different lengths?
search_vulns' version comparison works in the following way:
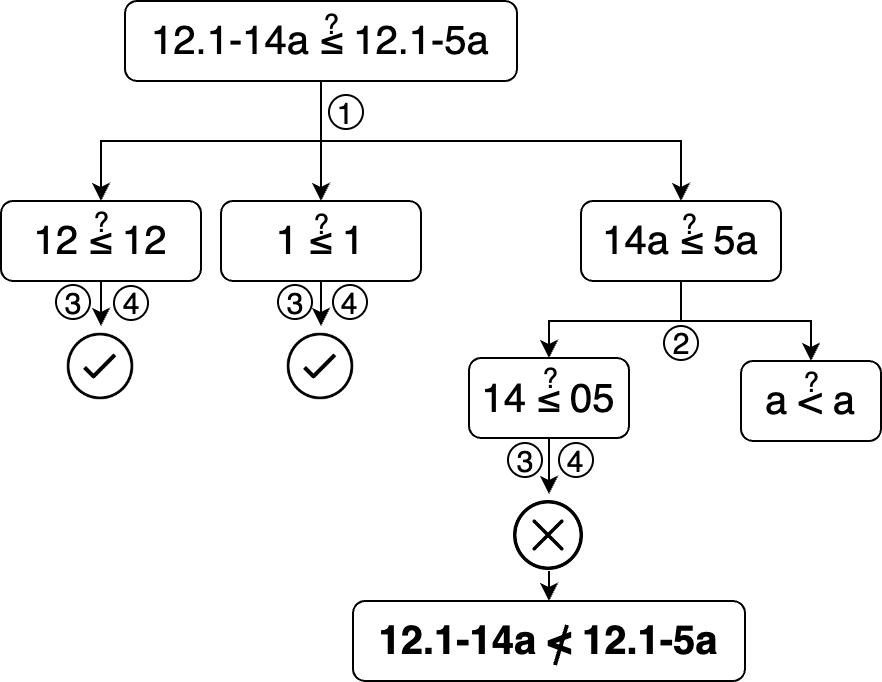
- Dissect both versions into segments, splitting at common subversion seperators like
.,-or_. For example,13.1-48.47is initially split into13,1,48,47. - Split version numbers further by character classes, e.g.
14su1consists of the parts14,suand1. - Starting from the front, compare the segments at the same index with each other.
- When comparing two numeric segments, make sure they are the same length and pad with zeroes on the left as necessary. Then, compare each character from the beginning of both segments to the end. Decide whether one character is smaller than another via its ASCII numeric value. Once a smaller character is found, the entire version the character belongs to is considered earlier.
- If all version segments are considered equal, the versions are considered equal. The greater than primitive is constructed from the less than and equal primitives.
While this is fairly straightforward, it's a core concept of how search_vulns works and gains an upper hand over tools that cannot handle more complex versions.
Unfortunately, version comparison does become more complex in reality as well. For example, consider the question whether 20.0.0-3446 is earlier or later than 20.0-3445. Furthermore, version 7.4p1 should be considered equal 7.4patch1. Lastly, the product name might sometimes be prefixed to the version like esxi70u1c-17325551 from CVE-2020-3999. Without being too in-depth, search_vulns attempts to overcome these challenges in the following ways:
.0extensions at the end of the initial version segments are dedupliced.patchis treated equal topandupdateequal tou.- search_vulns tries to detect this circumstance and prefix the unprefixed version in a comparison.
Generally Affected Products
Unfortunately, the NVD doesn't always manage the affected products and configurations of a product properly. Sometimes, the NVD states the product in general is vulnerable without specifying an upper version bound. For example, take a look at the configurations entry for CVE-2023-2422:
"descriptions": [
{
"lang": "en",
"value": "A flaw was found in Keycloak. A Keycloak server configured to support mTLS authentication for OAuth/OpenID clients does not properly verify the client certificate chain. A client that possesses a proper certificate can authorize itself as any other client, therefore, access data that belongs to other clients."
},
[...],
"configurations": [
{
"operator": "AND",
"nodes": [
{
"operator": "OR",
"negate": false,
"cpeMatch": [
{
"vulnerable": true,
"criteria": "cpe:2.3:a:redhat:keycloak:-:*:*:*:*:*:*:*",
"matchCriteriaId": "6E0DE4E1-5D8D-40F3-8AC8-C7F736966158"
}
This entry makes it seem like Keycloak in general is affected. This is not the case, however: the vulnerability was fixed in Keycloak 21.1.2. Still, if a tool relies on the NVD's data or MITRE's CVE description, it has to display it for every Keycloak version. For now, search_vulns is also affected by this, as are many other tools. In difference, search_vulns recognizes this circumstance and highlights these vulnerabilities with a warning:
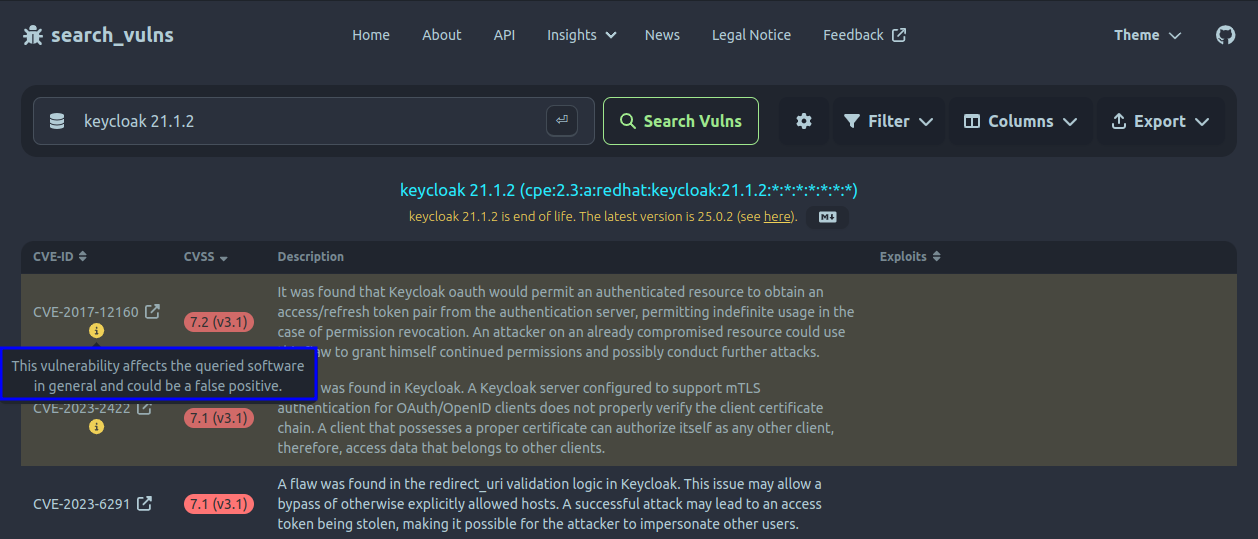
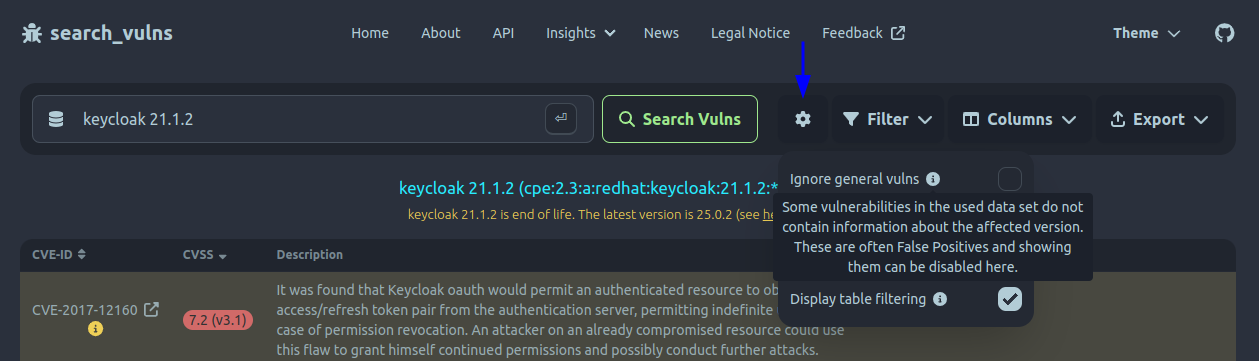
While search_vulns shows this vulnerabilities by default, it can be configured to omit them:
Only a Single Version of the Product Is Affected
This challenge is similar to the one before: The NVD does not manage the affected products of a vulnerability properly sometimes. Take a look at CVE-2020-15716:
"descriptions": [
{
"lang": "en",
"value": "RosarioSIS 6.7.2 is vulnerable to XSS, caused by improper validation of user-supplied input by the Preferences.php script. A remote attacker could exploit this vulnerability using the tab parameter in a crafted URL."
},
[...],
"configurations": [
{
"nodes": [
{
"operator": "OR",
"negate": false,
"cpeMatch": [
{
"vulnerable": true,
"criteria": "cpe:2.3:a:rosariosis:rosariosis:6.7.2:*:*:*:*:*:*:*",
"matchCriteriaId": "4A870F8E-3082-421C-A701-75D43DD6276C"
}
]
}
]
}
],
According to this entry, only RosarioSIS 6.7.2 is affected by the vulnerability. However, more detailed research suggests that earlier versions are also affected. If a tool relies on the NVD's data or MITRE's CVE description, it must display it only for version 6.7.2. For now, search_vulns is also affected by this problem, as are many other tools. In difference, again, search_vulns recognizes this circumstance, provides an option to display these vulnerabilities for any earlier versions as well and highlights them with a warning.
How Exploits and Other Information is Matched To Vulnerabilities
NVD entries sometimes contain references to exploits, which are directly incorporated into search_vulns results. In addition, search_vulns currently also includes PoC-in-GitHub and the Exploit-DB as exploit data sources. If an exploit relates to a CVE, both data sources provide the corresponding CVE-ID. Therefore, search_vulns can retrieve exploit references for a vulnerability via its CVE identifier.
Including Software Recency Status from endoflife.date Data
endoflife.date provides information about releases and support lifecycles of currently over 300 products. It is open source and maintains all of its code and product information inside its public GitHub repository. To work with this data offline, search_vulns builds a local copy of the required information. Unfortunately, endoflife.date does not provide CPE strings for its products yet. Therefore, search_vulns uses its subtool cpe_search during the build process to find a CPE string for every product. As a result, when a user queries for a product, search_vulns can easily retrieve the relevant endoflife.date data and provide the user with recency information:
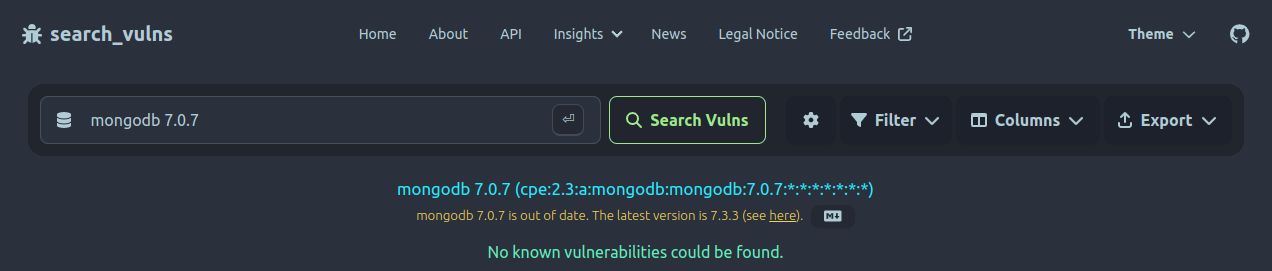
Recaptcha & API
Searching for CPEs and vulnerabilities with the methods we described above can become computationally expensive. Therefore, if an instance of the web server is deployed publicly, it should be protected from Denial of Service (DoS) attacks. To achieve this, we implemented CAPTCHA checks and an API key mechanism. These features can easily be configured on top of search_vulns' core, such that private instances do not need to use them.
For search_vulns' CAPTCHA checks we decided to utilize Google's reCAPTCHA. We deem reCAPTCHA reliable enough for our purposes and it is free to use for up to 1 million assessments per month. More specifically, we use reCAPTCHA v3 to protect the API endpoint that is used for issuing a vulnerability search. By using v3, the assessment happens automatically in the background without inconveniencing the user.
Of course we also want other programs to use our publicly accesible instance of search_vulns. Therefore, users can request an API key via the web site to use inside their programs. For now, API keys are limited to 60 requests in a five minute window. We may adjust this number in the future based on usage statistics and requests. Finally, users can also configure an API key in the web app if reCAPTCHA v3 fails for them.
Summary, Conclusion and Future Work
In our first post, we highlighted the need for an efficient and reliable solution to identify whether a software product is affected by any known vulnerabilities. At the same time, we discovered that all solutions we evaluated showed weaknesses with regards to the requirements we defined for a good solution. Most importantly, the solutions had difficulties with returning exactly the vulnerabilities the quried software is affected by. Other problems include input restrictions, date timeliness and exporting capabilities, rendering them less usable. For this reason, we decided to develop our own tool, search_vulns, that meets our defined requirements and solves their various challenges. In our second post, we introduced our tool, detailed some of its core features and conluded the comparison we started in the first post.
In this third post, we provided a deep dive into search_vulns' features and inner workings. We started by giving an overview of its (technical) architecture. Subsequently, we went into details about how search_vulns is able to allow unrestricted input by using text comparison techniques to match user input to a software ID / CPE. We also described how search_vulns enhances user queries by accepting software abbreviations or including software deprecations. Next, we illustrated how vulnerabilities for a software ID can be retrieved via the NVD's vulnerability data feed and how to deal with challenges in this data feed. We also highlighted how search_vulns provides references to exploits via additional information from the Exploit-DB or PoC-in-GitHub, or determines a software's recency status via endoflife.date.
In the future, we intend to continue developing search_vulns and implement more features. Most prominently, this includes adding more vulnerability and exploit data sources, like the Snyk Vulnerability Database, the GitHub Security Advisory Database, mvnrepository or 0day.today. Furthermore, we plan to add support for including information about Operating System backpatches.
Thank you for reading our posts. If you'd like to check out search_vulns, go to the home page and give it a try. Also, if you'd like to set up your own instance or would like to contribute, check out our tool's GitHub repository.